筆者個人非常喜歡「Money Ball」這部電影,在台灣上映時叫「魔球」。故事敘述奧克蘭運動家隊總經理Billy Beane摒棄傳統用重金追求明星球員的做法,改用數據分析的方式挑選球員籌建球隊,憑藉團隊戰力去贏得一場又一場的比賽,不僅打破美聯有史以來的連勝歷史紀錄,更創造出大聯盟所有球隊中贏下一場比賽所需成本最低的傳奇。
其實在現今的社會裡已經隨處可見數據分析對你我生活的影響。N-Partner公司的技術研發方向同樣專注在數據分析這個領域,應用於IT維運工作智慧化的相關需求上。以下簡單說明執行IT維運工作時所需的三種主要數據SNMP、Flow與Syslog其技術原理與功用:
(1) SNMP (Simple Network management Protocol) Polling
SNMP協定的主要用途是對於設備的健康狀態(例如CPU/Memory/溫度/風扇/Interface UP and Down等)進行監測。IT服務要能正常運作,首要關鍵就是所有佈署於網路的設備必須保持健康且運作無虞。透過SNMP協定採集設備的硬體運行參數,其工作目標就是要能發現運作異常的設備,提示管理人員即時採取修復措施避免IT服務品質受到影響。
(2) Flow (NetFlow, sFlow) Records Export
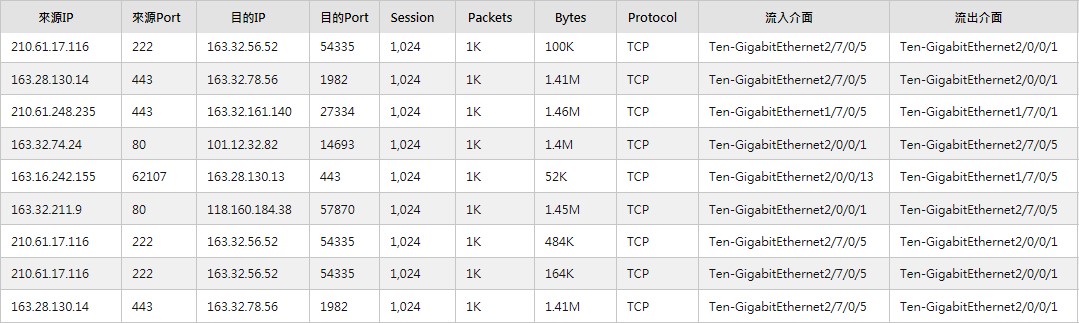
Flow的用途則是紀錄關於網路用量的訊息,諸如某個用戶端IP發送了多少封包(Packet)、總共傳送了多少量(Bytes)?某個伺服器接收了多少連線(Session)請求、回應了多少封包與多少Bytes?某個應用(ex: TCP 80)佔據多少頻寬等。藉由Flow訊息的分析能夠協助管理人員了解人們使用網路關於量大量小的問題。Flow訊息涵蓋OSI定義中的Layer 3與Layer 4。Flow資訊通常來自網路設備如路由器、核心交換器,或是資安設備如防火牆等。此外,流量分析技術更是協助解決網路世界裡日趨嚴重DDoS攻擊的有效手段。
圖1:Flow裡含有IP、Packet、Byte、Interface、TCP Flag等重要訊息
(3) Syslog Events Export
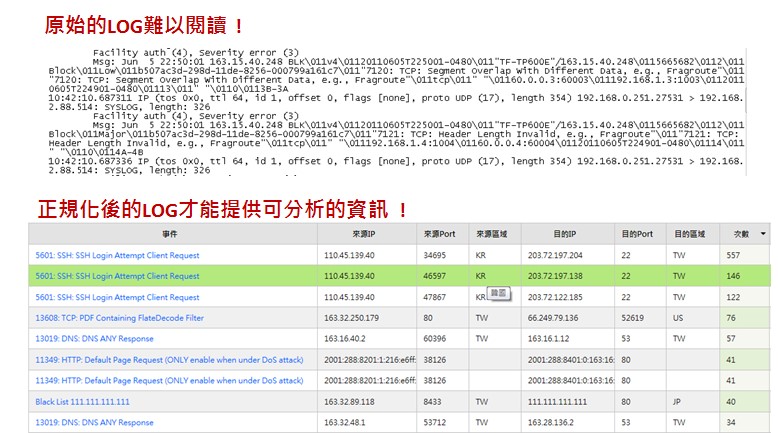
隨著資安意識的逐漸普及與提升,越來越多的網路環境選擇佈署安全防禦設備或是網路行為管控機制,針對封包裡第七層(Application Layer)內容進行檢查與處置。現況裡大多數品牌的網路與資安設備、電腦作業系統都已支援透過syslog協議將本機日誌(Log)輸出,方便管理人員進行分析工作,藉此掌握網路使用行為(ex: P2P下載、使用通訊軟體、瀏覽哪些網站等)以及跟資安相關的事件。Syslog訊息涵蓋OSI定義中的Layer 7。然而,不同廠牌設備其Syslog丟出的日誌的格式並不相同,日誌接收平台需要能夠辨識與讀懂不同型態的日誌,並且執行正規化(Normalization)切割,才能進行下一階段的分析工作。
圖2:日誌正規化後才容易讀懂並進行後續統計與分析工作
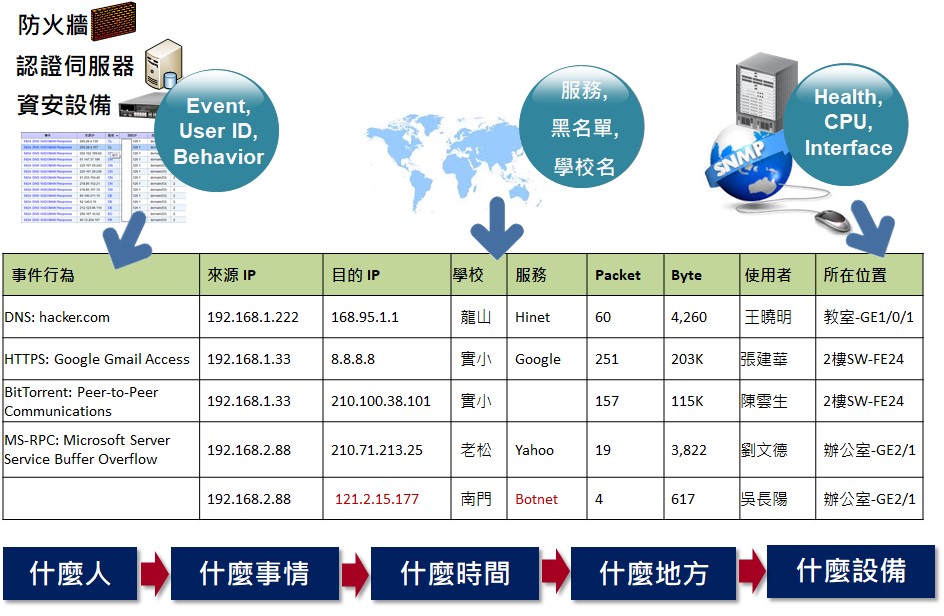
將三大網管技術加以整合是建構新一代維運體系框架的必要做法。因為每種技術各有專長也都有不足之處,整合得當將有助於管理人員窺知網路活動的全貌。Flow記錄兩個IP之間的傳輸用量統計,資料內容帶有Source IP、Source Port、Destination IP、Destination Port、Protocol、Packet、Byte 等。而Syslog日誌主要是說明發生了甚麼事件,資料內容包括事件名稱與說明、Source IP、Source Port、Destination IP、Destination Port、Protocol、事件發生次數(Hit Count)等。要將Flow與Syslog關聯在一起可以使用5 Tuples比對方式執行:單位時間裡(通常是1分鐘內) Source IP、Source Port、Destination IP、Destination Port、Protocol這5個參數相同者可以視為同一連線行為。接著,整合登入認證機制的日誌則能夠將IP的使用者名字比對出來。最後,透過SNMP的詢問就可以知道每個IP連接在哪個Switch的哪個Interface底下。N-Partner公司的數據分析技術將主動呈現異質資料間的關聯結果,省去人工比對查找所耗的時間。
圖3:SNMP/Flow/Syslog關聯整合可提供完整的使用行為訊息,無須繁瑣查找
本文揭櫫智慧化數據分析對IT維運工作有著莫大助益。然而要處理如此龐大的數據資料並不容易,加上Flow與Syslog資料內容迥異,要做好包含資料接收(Receive)、分類(Classify)、標記(Tagging)、儲存(Store)、搜尋(Search)、讀取(Read)、統計(Statistic)、人工智慧分析(AI Analysis)、告警(Alert)到報告(Reporting)以及記錄(Audit)等每個工作環節,非有全新的運算設計不可。
筆者用下方資料處理流程圖說明N-Partner公司的開發團隊如何能夠做到高效能的巨量數據處理:Syslog與Flow資料接收進來後存放入記憶體中執行正規化(Normalization)拆解,接著根據5 Tuples原理進行關聯比對(Correlation),加註標記(tagging)後離開記憶體以檔案的形式放入儲存空間等待後續的查詢與統計命令。
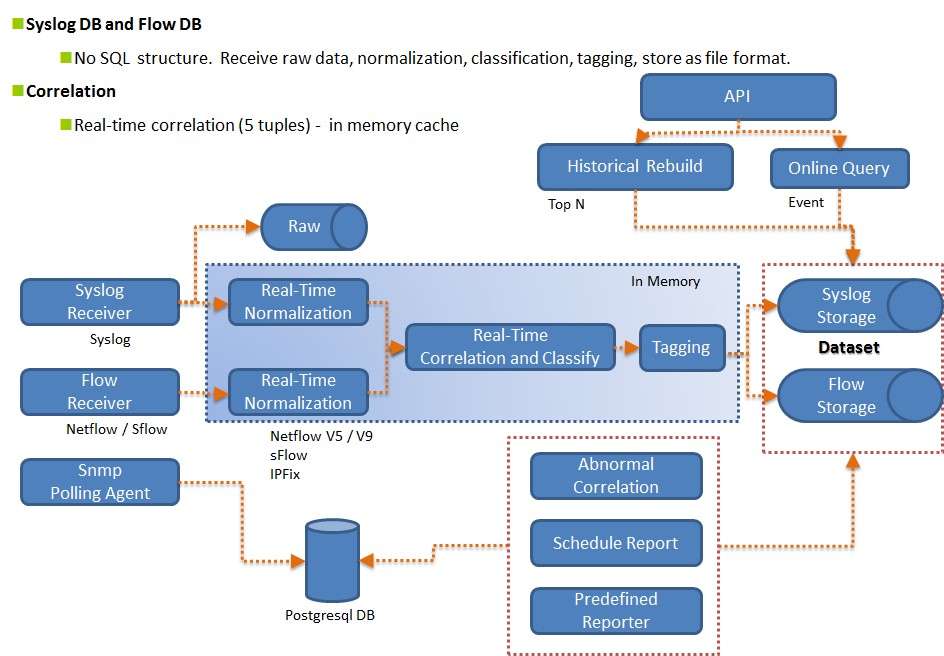 圖4:大數據處理流程
圖4:大數據處理流程
為了做到快速查詢,N-Partner公司的開發團隊摒棄傳統的關聯式資料庫(SQL)改採NoSQL作為資料儲存的架構。NoSQL有幾個優點:同時下達多個查詢條件時回應速度快、具有水平擴充能力以及沒有關聯式資料庫Schema欄位架構的限制,比起SQL更適合用作非結構性巨量數據儲存與處理的平台。
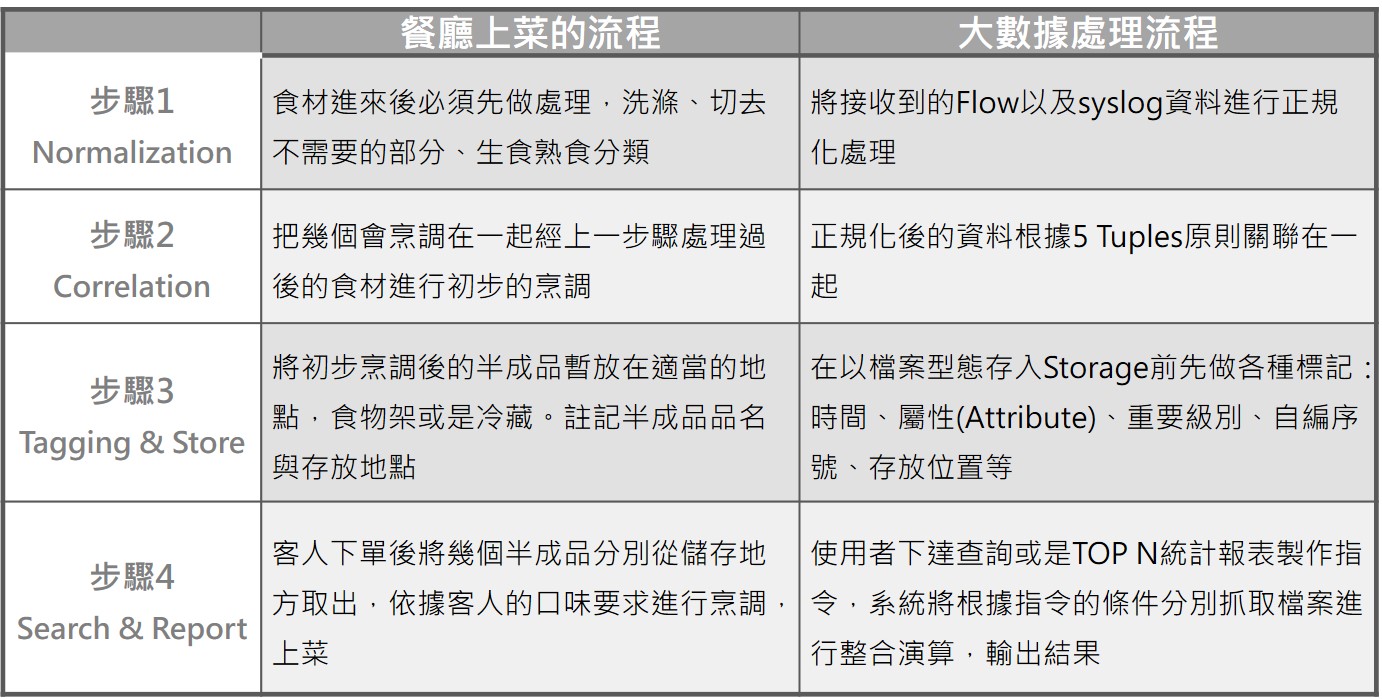
檔案儲存後要能快速而精準的找到,清楚標記的工作是關鍵。整個資料處理的過程可以想成餐廳上菜的步驟,餐廳上菜速度要快,通常是預先將食材處理成半成品後,再依據客戶下的訂單內容組合烹煮。請參看下表的對應說明: